Coleta de Dados
Acesse e responda o formulário abaixo.

Ou acesse diretamente:
https://forms.gle/XxyHkJ5rgEfuoJC18
🎲 Agora acesse e responda o segundo formulário.

Ou acesse diretamente:
https://forms.gle/pmyYVS8fXBk9E7eh9
Contrastando Hipóteses
Da formulação de modelos à razão de verossimilhanças
Probabilidade e Estatística
nas Ciências do Mar
📊 Monitorar ambientes marinhos e costeiros (praias, recifes, estuários, ...)
🐟 Estimar estado e trajetória de populações e comunidades marinhas
🌊 Modelar correntes oceânicas e processos físicos
🔬 Analisar dados ambientais e oceanográficos
🎯 Definir e avaliar estratégias de monitoramento e gestão ambiental
Tudo depende de confrontar dados com modelos
O que acabamos de fazer?
✅ Formulário 1: Dado mental (simulado mentalmente)
✅ Formulário 2: Dado físico (lançado de verdade)
✅ Experimento: O lançamento do dado físico serve de controle para o dado mental
✅ Os dados estão coletados, mas ninguém viu os resultados ainda!
Definir o que esperamos encontrar
Roteiro da Aula
- Formular expectativas (hipóteses) antes de observar os dados
- Traduzir hipóteses em modelos probabilísticos
- Explorar os dados: confrontar expectativa com observação
- Quantificar a compatibilidade entre modelos e dados (verossimilhança)
- Comparar as hipóteses: razão de verossimilhanças
Hipóteses Antes da Análise
O que esperamos encontrar nos 🎲?
Pensem no dado físico...
Se juntarmos os resultados de toda a turma em um gráfico de frequência,
como vocês esperam que o gráfico se pareça?
💭
O gráfico de frequência esperado
Se o dado for justo, esperamos que cada face apareça aproximadamente 1/6 das vezes
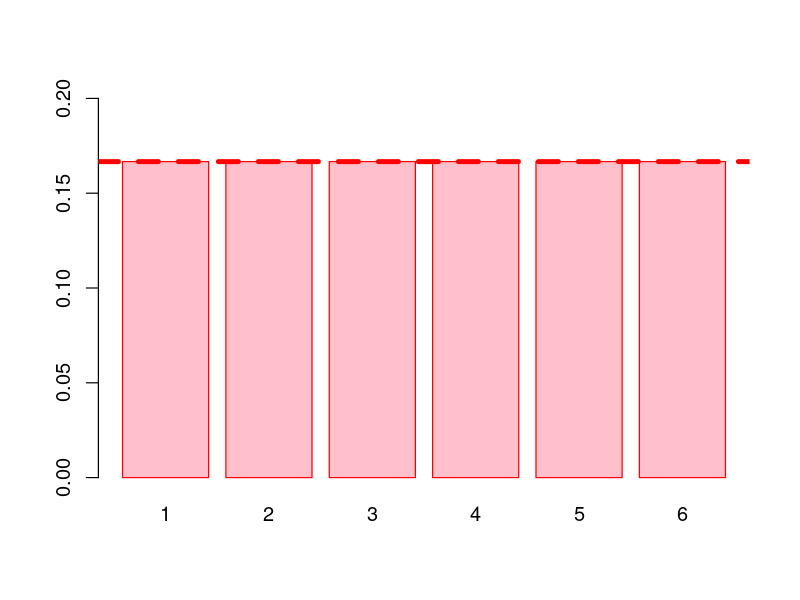
Gráfico de Frequência $\leftrightarrow$ Hipótese $\leftrightarrow$ Modelo
A expressão abaixo descreve um modelo probabilístico:
$$M_1: P(X = k) = \frac{1}{6} \text{ para todo } k$$
O modelo é uma representação matemática do que esperamos observar
se nossa hipótese do Dado
Justo for verdadeira
Variabilidade Natural
Mesmo com um dado perfeitamente justo, cada repetição do experimento produzirá resultados um pouco diferentes
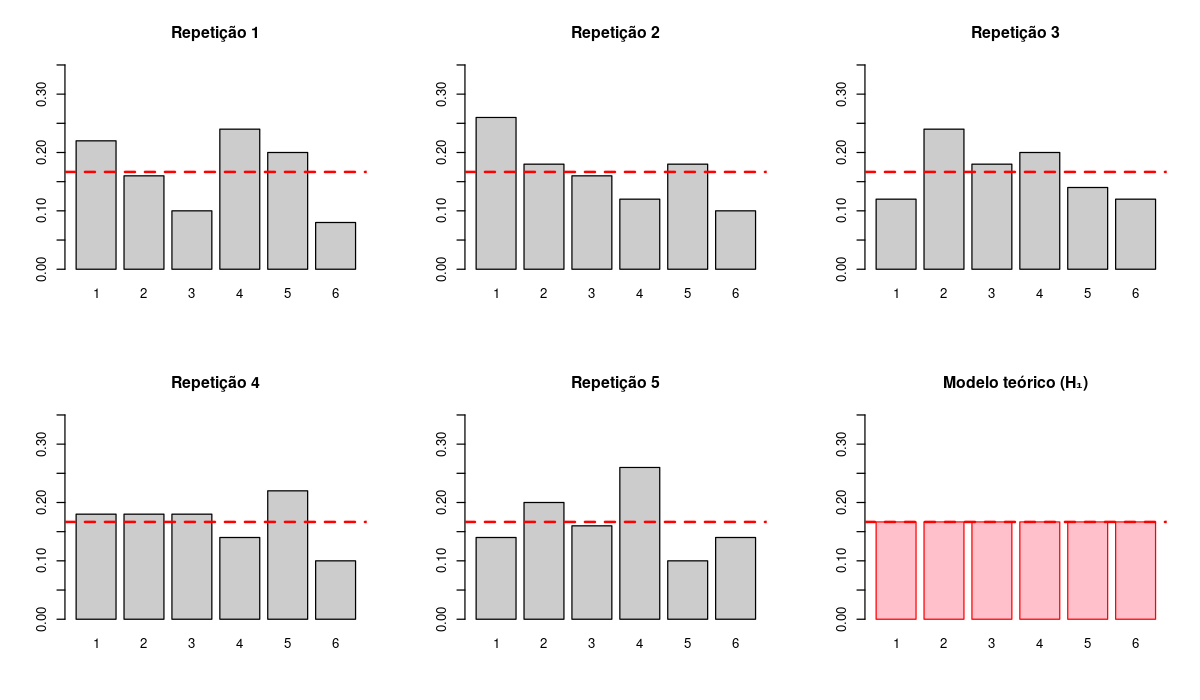
E o dado mental?
O padrão resultante vai produzir uma distribuição aproximadamente uniforme, parecida com a de um dado justo?
💭
Se não for uniforme...
🤔 Como vocês acham que seria?
Quais números tenderiam a ser escolhidos com mais ou menos frequência?
Hipótese 2: Viés Central
H₂: As pessoas preferem o centro e evitam os extremos
| Face | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| p | 1/14 | 2/14 | 4/14 | 4/14 | 2/14 | 1/14 |
Duas Hipóteses Definidas
H₁: Uniforme
Todas as faces igualmente prováveis
$$M_1: \quad p_k = \frac{1}{6}$$
H₂: Viés Central
Centro mais provável, extremos raros
$$M_2: \quad p_3 = p_4 = \frac{4}{14}$$
O Princípio Epistemológico
O que temos agora?
- Conjuntos de dados experimentalmente robustos (controle + tratamento)
- Duas hipóteses formuladas antes de abrir qualquer resultado
- Um modelo probabilístico específico para cada hipótese
- Uma percepção coletiva sobre qual hipótese é mais plausível
- Ainda não vimos os dados!
Explorando os Dados
Confrontando Expectativa com Realidade
Lendo a planilha de dados
e visualizando o gráfico de frequências
Hipóteses $\leftrightarrow$ Modelos $\leftrightarrow$ Dados
Temos duas hipóteses,
cada uma descrita por um
modelo probabilístico diferente
Como quantificar o modelo mais compatível com os dados?
Verossimilhança
Quantificando a Compatibilidade entre Hipóteses e Dados
A Lógica da Verossimilhança
Se temos um modelo que atribui probabilidades a cada resultado possível de um experimento, podemos medir quão compatível o modelo é com os dados que de fato temos em mãos.
A verossimilhança é a função que associa os dados a este modelo de probabilidade.
Probabilidade $\neq$ Verossimilhança
Probabilidade
Olha para frente: dado um modelo, qual a chance de observar um resultado?
$$P(\text{dados} \mid H)$$
O modelo é fixo, o resultado varia
Verossimilhança
Olha para trás: dado que observamos um resultado, quão plausível é o modelo?
$$\mathcal{L}(H;\text{dados})$$
Os dados são fixos, o modelo varia
O valor numérico de $\mathcal{L}(H;\text{dados})$ é calculado como $P(\text{dados} \mid H)$. A diferença está na interpretação: a verossimilhança mede a plausibilidade de hipóteses, não de resultados.
Fórmula da Verossimilhança para 🎲
$$\mathcal{L}(H;\text{dados}) = \prod_{k=1}^{6} p_k^{n_k}$$
Onde $p_k$ é a probabilidade que o modelo atribui à face $k$,
e $n_k$ é quantas vezes essa face apareceu
Em log (mais prático para computação):
$$\log \mathcal{L}(H;\text{dados}) = \sum_{k=1}^{6} n_k \cdot \log(p_k)$$
Entendendo a fórmula da verossimilhança
Calculando no R: verossimilhança de H₁
# Definir as probabilidades associadas ao modelo H1
p_h1 <- rep(1/6, 6)
# Calcular a log-verossimilhança para o dado físico
loglik_h1_fisico <- sum(freq_fisico * log(p_h1))
# Calcular a log-verossimilhança para o dado mental
loglik_h1_mental <- sum(freq_mental * log(p_h1))
A necessidade de hipóteses múltiplas
Na ciência, nunca avaliamos uma hipótese isoladamente.
Sempre comparamos:
este modelo versus aquele modelo
esta explicação versus aquela explicação
Calculando no R: verossimilhança de H₂
# Definir as probabilidades associadas ao modelo H2
p_h2 <- c(1, 2, 4, 4, 2, 1) / 14
# Calcular a log-verossimilhança para o dado físico
loglik_h2_fisico <- sum(freq_fisico * log(p_h2))
# Calcular a log-verossimilhança para o dado mental
loglik_h2_mental <- sum(freq_mental * log(p_h2))
Razão de Verossimilhanças
A Comparação em Ação
$$\Lambda = \frac{\mathcal{L}(H_2;\text{dados})}{\mathcal{L}(H_1;\text{dados})}$$
$$\log \Lambda = \sum_{k=1}^{6} n_k \cdot \log\!\left(\frac{p_k^{(H_2)}}{p_k^{(H_1)}}\right)$$
Para cada face, medimos o quanto H₂ prevê a mais ou a menos que H₁, ponderado pelo número de vezes que a face apareceu
Interpretação da Razão de Verossimilhanças
$$\Lambda = \frac{\mathcal{L}(H_2;\text{dados})}{\mathcal{L}(H_1;\text{dados})}$$
| $\Lambda > 1$ ($\log\Lambda > 0$) | dados mais compatíveis com $H_2$ do que com $H_1$ |
| $\Lambda < 1$ ($\log\Lambda < 0$) | dados mais compatíveis com $H_1$ |
| $\Lambda = 1$ | os dois modelos explicam os dados igualmente bem |
| $\Lambda = 10$ | $H_2$ é 10 vezes mais compatível com os dados do que $H_1$ |
Calculando a razão de verossimilhanças no R
Comparando H₁ e H₂ para cada tipo de lançamento
lambda_mental <- exp(loglik_h2_mental - loglik_h1_mental)
lambda_fisico <- exp(loglik_h2_fisico - loglik_h1_fisico)
cat("Razão H2/H1 — dado mental:", round(lambda_mental, 2), "\n")
cat("Razão H2/H1 — dado físico:", round(lambda_fisico, 2), "\n")
Recapitulando a Aula 01
| Etapa | O que fizemos | Conceito formal |
|---|---|---|
| 1. Experimentação | Geramos dados sob duas condições experimentais (dado mental e dado físico) | Desenho experimental e grupo controle |
| 2. Expectativas | Formulamos previsões antes de ver os resultados | Hipóteses H₁ e H₂. Raciocínio hipotético-dedutivo |
| 3. Modelos probabilísticos | Traduzimos as intuições em dois modelos concorrentes com probabilidades explícitas | Modelo probabilístico e aleatoriedade |
| 4. Análise exploratória | Confrontamos os gráficos de frequência com as expectativas dos modelos | Análise exploratória guiada por hipótese |
| 5. Razão de verossimilhanças | Quantificamos qual modelo é mais compatível com os dados observados | Verossimilhança e razão $\Lambda$ |