library(tidyverse)
library(patchwork)
library(gt)
library(knitr)Partição da soma dos quadrados e coeficiente de determinação na regressão linear
Regressão linear
Estatística
Soma dos quadrados
Coeficiente de determinação
Decomposição da variabilidade total em componentes da regressão e do resíduo. Derivação e interpretação do coeficiente de determinação \(R^2\).
DicaPacotes e funções utilizadas no capítulo
Ao ajustar um modelo de regressão linear simples, obtemos a reta que minimiza a soma dos quadrados dos resíduos (\(SQ_{Res}\)). Um aspecto fundamental deste processo consiste em compreender qual a proporção da variação total em \(Y\) o modelo é capaz de explicar? Para responder a esta pergunta, precisamos decompor a variação total de \(Y\) em duas parcelas distintas: uma atribuída à regressão e outra atribuída aos resíduos. Este processo é conhecido como partição da soma dos quadrados.
Recordando o modelo de regressão linear simples:
\[Y_i = \hat{\beta}_0 + \hat{\beta}_1 X_i + e_i\]
onde \(\hat{Y}_i = \hat{\beta}_0 + \hat{\beta}_1 X_i\) é o valor ajustado e \(e_i = Y_i - \hat{Y}_i\) é o resíduo da \(i\)-ésima observação.
1 Os três componentes da variação
Consideremos \(n\) pares de observações \((X_i, Y_i)\) com \(i = 1, \ldots, n\). Definimos três quantidades fundamentais.
Soma dos Quadrados Total (\(SQ_{Total}\)): mede a variação total de \(Y\) em torno de sua média \(\bar{Y}\), independentemente do modelo de regressão.
\[SQ_{Total} = \sum_{i=1}^{n}(Y_i - \bar{Y})^2\]
Soma dos Quadrados da Regressão (\(SQ_{Reg}\)): mede a variação nos valores ajustados \(\hat{Y}_i\) em torno de \(\bar{Y}\). Representa a parcela da variação total que é explicada pela variável preditora \(X\).
\[SQ_{Reg} = \sum_{i=1}^{n}(\hat{Y}_i - \bar{Y})^2\]
Soma dos Quadrados dos Resíduos (\(SQ_{Res}\)): mede a variação dos valores observados em torno dos valores ajustados. Representa a parcela da variação total que não é explicada pelo modelo, atribuída ao erro.
\[SQ_{Res} = \sum_{i=1}^{n}(Y_i - \hat{Y}_i)^2\]
NotaAs três somas dos quadrados
| Componente | Expressão | Interpretação |
|---|---|---|
| \(SQ_{Total}\) | \(\sum (Y_i - \bar{Y})^2\) | Variação total em \(Y\) |
| \(SQ_{Reg}\) | \(\sum (\hat{Y}_i - \bar{Y})^2\) | Variação explicada pelo modelo |
| \(SQ_{Res}\) | \(\sum (Y_i - \hat{Y}_i)^2\) | Variação não explicada (resíduo) |
A figura abaixo ilustra os três desvios para uma observação qualquer \((X_k, Y_k)\).
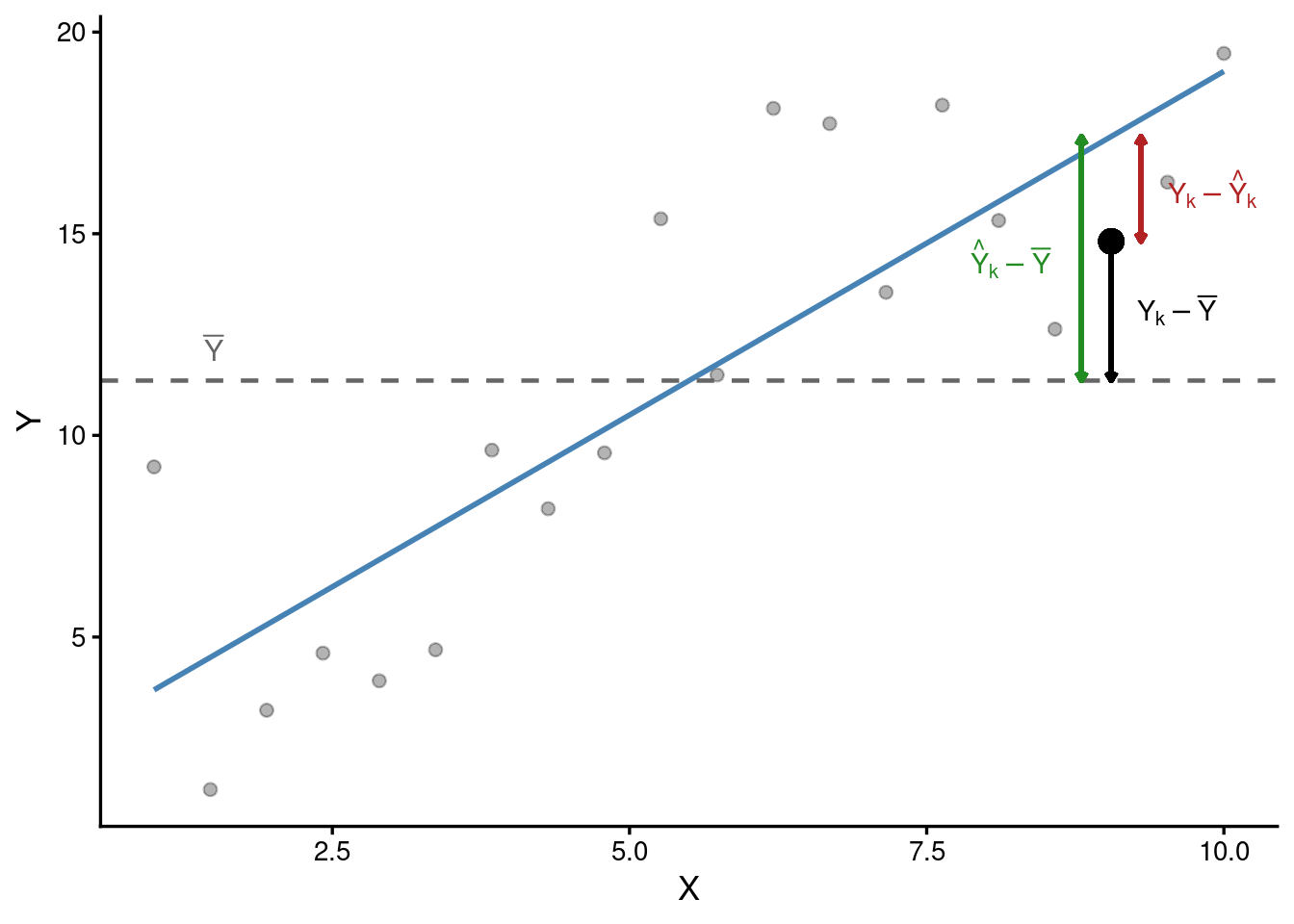
A linha tracejada horizontal representa \(\bar{Y}\). Para o ponto destacado, podemos observar:
- O desvio total (\(Y_k - \bar{Y}\), em preto) é a soma do desvio da regressão e do resíduo.
- O desvio da regressão (\(\hat{Y}_k - \bar{Y}\), em verde) é a porção do desvio total capturada pelo modelo.
- O resíduo (\(Y_k - \hat{Y}_k\), em vermelho) é o que sobra após o ajuste.
Uma propriedade da decomposição da soma dos quadrados é que \(SQ_{Total} = SQ_{Reg} + SQ_{Res}\) portanto:
NotaPartição da soma dos quadrados na regressão linear
\[SQ_{Total} = SQ_{Reg} + SQ_{Res}\]
\[\sum_{i=1}^{n}(Y_i - \bar{Y})^2 = \sum_{i=1}^{n}(\hat{Y}_i - \bar{Y})^2 + \sum_{i=1}^{n}(Y_i - \hat{Y}_i)^2\]
2 O coeficiente de determinação \(R^2\)
2.1 Definição e interpretação
A partição da soma dos quadrados nos permite definir o coeficiente de determinação \(R^2\) como a proporção da variação total em \(Y\) que é explicada pelo modelo de regressão:
NotaCoeficiente de determinação
\[R^2 = \frac{SQ_{Reg}}{SQ_{Total}} = 1 - \frac{SQ_{Res}}{SQ_{Total}}\]
Como \(0 \le SQ_{Reg} \le SQ_{Total}\), temos \(0 \le R^2 \le 1\).
- \(R^2 = 0\): o modelo não explica nenhuma variação em \(Y\); a reta ajustada é horizontal (\(\hat{\beta}_1 = 0\)) e \(SQ_{Reg} = 0\).
- \(R^2 = 1\): o modelo explica toda a variação em \(Y\); todos os pontos estão exatamente sobre a reta de regressão e \(SQ_{Res} = 0\).
- \(0 < R^2 < 1\): situação usual, em que o modelo explica uma fração \(R^2 \times 100\%\) da variação total.
2.2 Formulações alternativas
\(SQ_{Reg}\) pode ser expresso em termos dos coeficientes do modelo e dos somatórios dos quadrados. Como \(\hat{Y}_i - \bar{Y} = \hat{\beta}_1(X_i - \bar{X})\):
\[SQ_{Reg} = \sum_{i=1}^{n}(\hat{Y}_i - \bar{Y})^2 = \hat{\beta}_1^2 \sum_{i=1}^{n}(X_i - \bar{X})^2 = \hat{\beta}_1^2 \cdot SQ_X\]
Substituindo \(\hat{\beta}_1 = SQ_{XY}/SQ_X\):
\[SQ_{Reg} = \frac{SQ_{XY}^2}{SQ_X^2} \cdot SQ_X = \frac{SQ_{XY}^2}{SQ_X} = \hat{\beta}_1 \cdot SQ_{XY}\]
onde \(SQ_{XY} = \sum(X_i - \bar{X})(Y_i - \bar{Y})\) é o produto cruzado de \(X\) e \(Y\), e \(SQ_X = \sum(X_i - \bar{X})^2\).
2.3 Relação com o coeficiente de correlação
Na regressão linear simples, \(R^2\) é exatamente igual ao quadrado do coeficiente de correlação de Pearson \(r\):
\[R^2 = r^2\]
Demonstração. Partindo de \(R^2 = SQ_{Reg}/SQ_{Total} = SQ_{XY}^2 / (SQ_X \cdot SQ_Y)\):
\[R^2 = \frac{SQ_{XY}^2}{SQ_X \cdot SQ_Y} = \left(\frac{SQ_{XY}}{\sqrt{SQ_X \cdot SQ_Y}}\right)^2 = r^2\]
Esta relação é exclusiva da regressão simples. Na regressão múltipla, \(R^2\) generaliza o conceito de correlação, mas não é simplesmente o quadrado de uma correlação bivariada.
2.4 Limitações do \(R^2\)
Embora \(R^2\) seja uma medida de ajuste amplamente utilizada, é importante reconhecer suas limitações:
\(R^2\) não mede causalidade. Uma associação forte entre \(Y\) e \(X\) não implica que \(X\) cause \(Y\). Uma terceira variável pode ser responsável pela associação observada.
\(R^2\) depende da amplitude de \(X\). Ampliar o intervalo dos valores de \(X\) tende a aumentar \(SQ_{Reg}\) e, consequentemente, \(R^2\), mesmo que a dispersão ao redor da reta não mude.
\(R^2\) alto não garante bom ajuste. Um modelo pode ter \(R^2\) elevado e ainda apresentar padrões sistemáticos nos resíduos, indicando violação de suposições do modelo.
\(R^2\) baixo não invalida o modelo. Em muitas aplicações nas ciências biológicas e sociais, \(R^2\) moderados (0,3–0,5) já refletem relações substantivas e interpretáveis.
\(R^2\) não é comparável entre conjuntos de dados. Dois modelos com \(R^2\) iguais em datasets diferentes não têm necessariamente a mesma qualidade de ajuste.
3 Situações extremas
Para compreender melhor o significado de \(R^2\), vamos simular dois cenários contrastantes: um com \(R^2\) elevado e outro com \(R^2\) baixo.
set.seed(1)
n_sim <- 60
X_sim <- seq(1, 10, length.out = n_sim)
y_det <- 5 + 3 * X_sim
# Cenário 1: R² alto (dispersão pequena em torno da reta)
Y_alto <- y_det + rnorm(n_sim, sd = 1.5)
# Cenário 2: R² baixo (dispersão grande em torno da reta)
Y_baixo <- y_det + rnorm(n_sim, sd = 12)3.1 Cenário com \(R^2\) elevado
df_alto <- data.frame(X = X_sim, Y = Y_alto)
mod_alto <- lm(Y ~ X, data = df_alto)
# Cálculo manual das somas dos quadrados
Ybar_alto <- mean(Y_alto)
Yfit_alto <- fitted(mod_alto)
SQTotal_alto <- sum((Y_alto - Ybar_alto)^2)
SQReg_alto <- sum((Yfit_alto - Ybar_alto)^2)
SQRes_alto <- sum((Y_alto - Yfit_alto)^2)
# Verificação: SQTotal = SQReg + SQRes
cat("SQTotal:", round(SQTotal_alto, 2), "\n")SQTotal: 3870.97 cat("SQReg:", round(SQReg_alto, 2), "\n")SQReg: 3773.89 cat("SQRes:", round(SQRes_alto, 2), "\n")SQRes: 97.08 # R² manual
R2_alto_manual <- SQReg_alto / SQTotal_alto
cat("R² (manual):", round(R2_alto_manual, 4), "\n")R² (manual): 0.9749 3.2 Cenário com \(R^2\) baixo
df_baixo <- data.frame(X = X_sim, Y = Y_baixo)
mod_baixo <- lm(Y ~ X, data = df_baixo)
# Cálculo manual das somas dos quadrados
Ybar_baixo <- mean(Y_baixo)
Yfit_baixo <- fitted(mod_baixo)
SQTotal_baixo <- sum((Y_baixo - Ybar_baixo)^2)
SQReg_baixo <- sum((Yfit_baixo - Ybar_baixo)^2)
SQRes_baixo <- sum((Y_baixo - Yfit_baixo)^2)
# Verificação: SQTotal = SQReg + SQRes
cat("SQTotal:", round(SQTotal_baixo, 2), "\n")SQTotal: 10346.4 cat("SQReg:", round(SQReg_baixo, 2), "\n")SQReg: 3262.46 cat("SQRes:", round(SQRes_baixo, 2), "\n")SQRes: 7083.93 # R² manual
R2_baixo_manual <- SQReg_baixo / SQTotal_baixo
cat("R² (manual):", round(R2_baixo_manual, 4), "\n")R² (manual): 0.3153 3.3 Visualização dos dois cenários
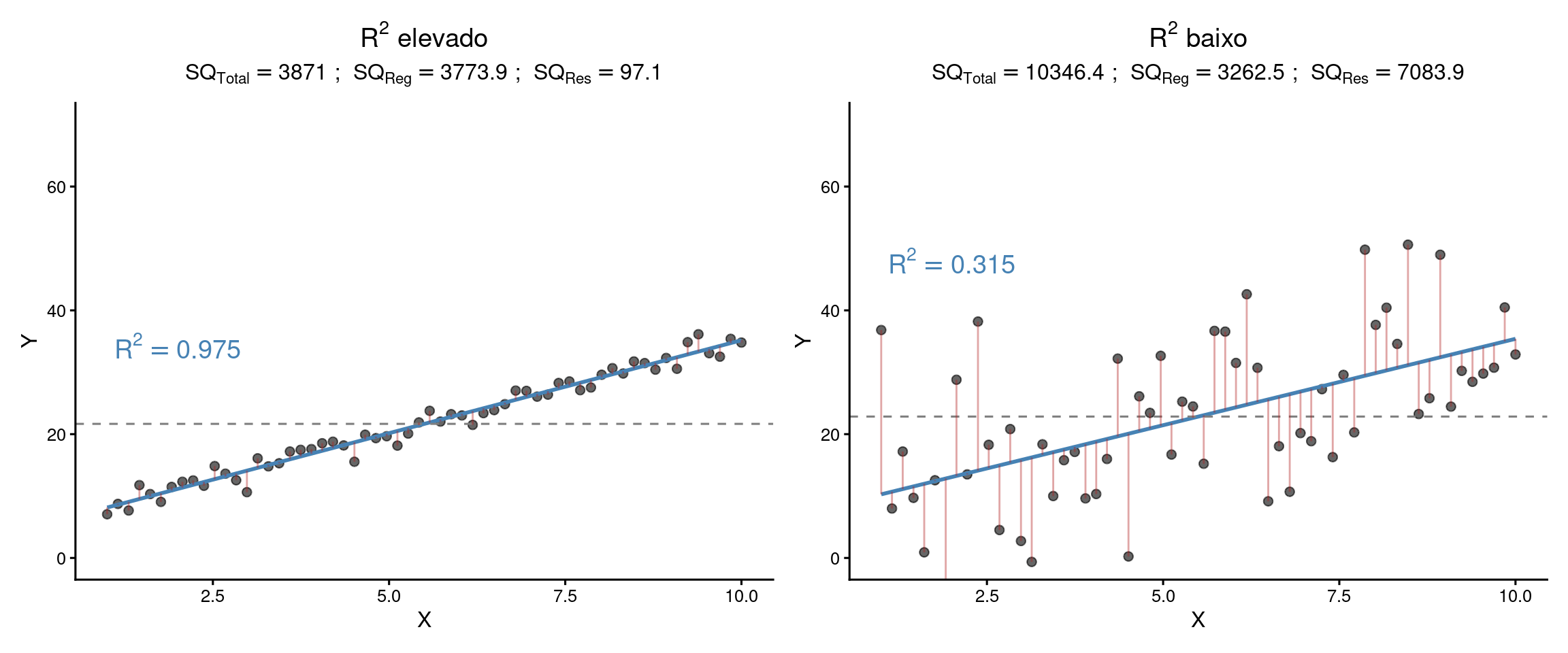
Em ambos os cenários, a reta de regressão apresenta a mesma inclinação populacional (\(\beta_1 = 3\)), o que produz valores de \(SQ_{Reg}\) bastante semelhantes. A diferença fundamental reside na variância residual. Na figura à esquerda, os pontos estão fortemente concentrados em torno da reta, o que implica um \(SQ_{Res}\) relativamente pequeno em comparação com a variação total (\(SQ_{Total}\)) e, consequentemente, um \(R^2\) elevado (\(SQ_{Res} = 97.08\), \(R^2 = 0.975\)). Em contraste, na figura à direita, observa-se maior dispersão dos pontos em torno da reta ajustada, resultando em um \(SQ_{Res}\) mais elevado e, portanto, em um \(R^2\) mais baixo (\(SQ_{Res} = 7083.93\), \(R^2 = 0.315\)).
4 Exemplo aplicado: dados RIKZ
Vamos aplicar todos os conceitos ao conjunto de dados RIKZ, que contém medidas de riqueza de macro-fauna praial (número de espécies) e o índice de exposição às ondas (NAP) coletados em \(45\) amostras ao longo da costa da Holanda (Zuur et al. 2009).
rikz <- read_csv('https://raw.githubusercontent.com/FCopf/datasets/refs/heads/main/RIKZ.csv')4.1 Ajuste do modelo
mod_rikz <- lm(Richness ~ NAP, data = rikz)O modelo ajustado é:
\[\widehat{Richness} = 6.686 + (-2.867) \times NAP\]
4.2 Cálculo manual das somas dos quadrados
n_rk <- nrow(rikz)
Ybar_rk <- mean(rikz$Richness)
Yfit_rk <- fitted(mod_rikz)
Yres_rk <- residuals(mod_rikz)
SQTotal_rk <- sum((rikz$Richness - Ybar_rk)^2)
SQReg_rk <- sum((Yfit_rk - Ybar_rk)^2)
SQRes_rk <- sum(Yres_rk^2)
cat("SQTotal:", round(SQTotal_rk, 3), "\n")SQTotal: 1101.644 cat("SQReg: ", round(SQReg_rk, 3), "\n")SQReg: 357.529 cat("SQRes: ", round(SQRes_rk, 3), "\n")SQRes: 744.115 cat("Verificação (SQReg + SQRes):", round(SQReg_rk + SQRes_rk, 3), "\n")Verificação (SQReg + SQRes): 1101.644 A tabela abaixo apresenta os primeiros valores da decomposição para cada observação:
Código
rikz |>
mutate(
Yfit = Yfit_rk,
Yres = Yres_rk,
dev_total = Richness - Ybar_rk,
dev_reg = Yfit_rk - Ybar_rk,
dev_res = Yres_rk
) |>
select(Richness, NAP, Yfit, dev_total, dev_reg, dev_res) |>
round(3) |>
slice_head(n = 10) |>
gt() |>
cols_label(
Richness = "Richness",
NAP = "NAP",
Yfit = gt::md("$\\hat{Y}_i$"),
dev_total = gt::md("$Y_i - \\bar{Y}$"),
dev_reg = gt::md("$\\hat{Y}_i - \\bar{Y}$"),
dev_res = gt::md("$Y_i - \\hat{Y}_i$")
) |>
fmt_number(decimals = 3)| Richness | NAP | \(\hat{Y}_i\) | \(Y_i - \bar{Y}\) | \(\hat{Y}_i - \bar{Y}\) | \(Y_i - \hat{Y}_i\) |
|---|---|---|---|---|---|
| 11.000 | 0.045 | 6.557 | 5.311 | 0.868 | 4.443 |
| 10.000 | −1.036 | 9.656 | 4.311 | 3.967 | 0.344 |
| 13.000 | −1.336 | 10.516 | 7.311 | 4.827 | 2.484 |
| 11.000 | 0.616 | 4.920 | 5.311 | −0.769 | 6.080 |
| 10.000 | −0.684 | 8.647 | 4.311 | 2.958 | 1.353 |
| 8.000 | 1.190 | 3.274 | 2.311 | −2.415 | 4.726 |
| 9.000 | 0.820 | 4.335 | 3.311 | −1.354 | 4.665 |
| 8.000 | 0.635 | 4.865 | 2.311 | −0.824 | 3.135 |
| 19.000 | 0.061 | 6.511 | 13.311 | 0.822 | 12.489 |
| 17.000 | −1.334 | 10.510 | 11.311 | 4.821 | 6.490 |
4.3 Verificação com funções do R
As somas dos quadrados podem ser extraídas diretamente da tabela ANOVA da regressão:
anova(mod_rikz)Analysis of Variance Table
Response: Richness
Df Sum Sq Mean Sq F value Pr(>F)
NAP 1 357.53 357.53 20.66 4.418e-05 ***
Residuals 43 744.12 17.31
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1As somas dos quadrados estão na coluna Sum sq. A primeira linha (NAP) corresponde a \(SQ_{Reg} = 357.53\) e a segunda linha (Residuals) a \(SQ_{Res} = 744.12\). Confirmamos que estes valores coincidem com os calculados manualmente. O \(SQ_{Total}\) não aparece na tabela mais pode ser facilmente obtido pela soma dos outros dois.
O coeficiente de determinação \(R^2\) pode ser obtido pela função summary:
R2_rk_func <- summary(mod_rikz)$r.squared
cat("R² (summary):", round(R2_rk_func, 4), "\n")R² (summary): 0.3245 # Relação com o coeficiente de correlação de Pearson
r_rk <- cor(rikz$Richness, rikz$NAP)
cat("r² (Pearson):", round(r_rk^2, 4), "\n")r² (Pearson): 0.3245 Os três valores são idênticos, confirmando a relação \(R^2 = r^2\) na regressão simples.
4.4 Interpretação
O modelo de regressão linear \(Richness \sim NAP\) explica 32.5% da variação total na riqueza de espécies (\(R^2 = 0.3245\)). Em termos das somas dos quadrados:
\[SQ_{Total} = SQ_{Reg} + SQ_{Res}\] \[1101.6 = 357.5 + 744.1\]
Os 67.6% restantes da variação não são explicados pelo NAP e estão atribuídos ao resíduo — podem refletir a influência de outras variáveis ambientais, variação natural entre espécies ou erros de medição.
4.5 Visualização da partição
Código
df_rikz_plot <- rikz |>
mutate(
Yfit = Yfit_rk,
Ybar = Ybar_rk
)
ggplot(df_rikz_plot, aes(x = NAP, y = Richness)) +
geom_hline(yintercept = Ybar_rk, linetype = "dashed",
color = "gray40", linewidth = 0.8) +
# Desvios da regressão (verde): Ybar -> Yfit
geom_segment(
aes(xend = NAP, y = Ybar, yend = Yfit, color = "reg"),
alpha = 0.5, linewidth = 0.8
) +
# Resíduos (vermelho): Yfit -> Y
geom_segment(
aes(xend = NAP, y = Yfit, yend = Richness, color = "res"),
alpha = 0.5, linewidth = 0.8
) +
geom_smooth(method = "lm", se = FALSE, color = "steelblue", linewidth = 1.2) +
geom_point(size = 2.5, alpha = 0.8) +
annotate("text", x = min(rikz$NAP) + 0.2, y = Ybar_rk + 1.8,
label = expression(bar(Y)), size = 4.5, color = "gray40") +
annotate("text", x = 2.2, y = 18,
label = as.expression(bquote(R^2 == .(R2_rk))),
size = 5, color = "steelblue") +
scale_color_manual(
name = "Partição da Soma dos Quadrados",
values = c(reg = "forestgreen", res = "firebrick"),
breaks = c("reg", "res"),
labels = c(
reg = expression(hat(Y)[i] - bar(Y) ~ "(desvio explicado)"),
res = expression(Y[i] - hat(Y)[i] ~ "(resíduo)")
)
) +
labs(x = "NAP", y = "Richness (n° de espécies)", color = NULL) +
theme_classic(base_size = 13) +
theme(legend.position = "bottom")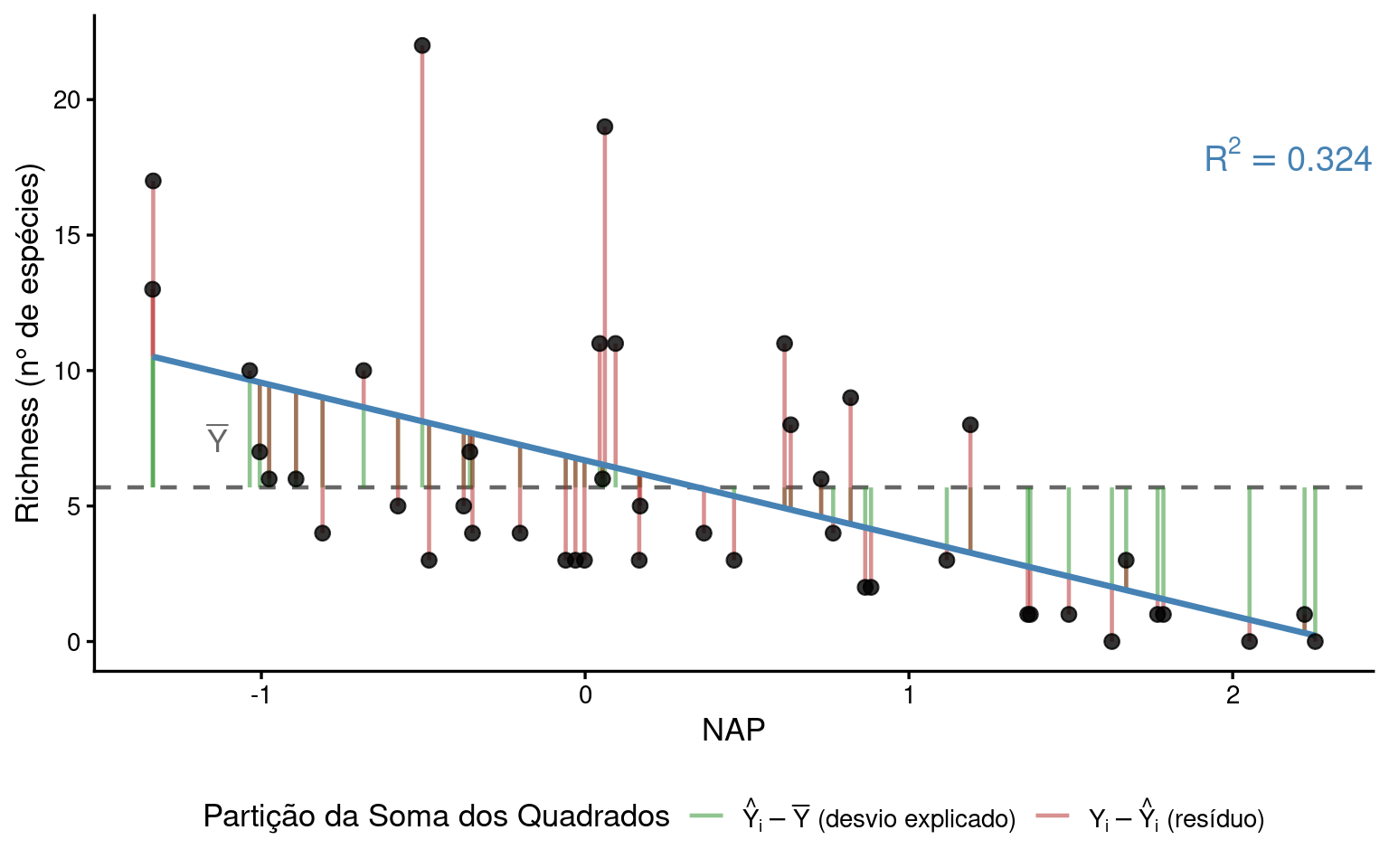
Na Figura 1, os segmentos verdes representam os desvios de \(\hat{Y}_i\) em relação a \(\bar{Y}\) (\(SQ_{Reg}\)) e os segmentos vermelhos representam os resíduos \(e_i = Y_i - \hat{Y}_i\) (\(SQ_{Res}\)). A soma dos quadrados de todos os segmentos verdes mais a soma dos quadrados de todos os segmentos vermelhos é igual à soma dos quadrados de todos os desvios totais (\(SQ_{Total}\)).
Referências
Zuur, Alain, Elena N Ieno, Neil Walker, Anatoly A Saveliev, e Graham M Smith. 2009. Mixed effects models and extensions in ecology with R. Springer Science & Business Media.